Introduction
This benchmark was built for the Google DeepMind × Kaggle Measuring Progress Toward AGI — Cognitive Abilities hackathon, which asks participants to design evaluations that isolate specific cognitive abilities rather than lumping them together under “general reasoning.” The hackathon is organized around the five-faculty framework in Burnell et al. (2026), Measuring progress toward AGI: A cognitive framework. Our submission targets the Executive Functions track — specifically planning, the ability to formulate sequences of future actions to achieve a goal.
Planning is notoriously hard to isolate. As Ryan Burnell put it during the hackathon livestream, many existing benchmarks “give a complex problem and just require the model to solve it but [don’t] really tap into any specific component of executive functions.” A model can score well on a reasoning benchmark while still being bad at the things planning actually asks of it: respecting multiple interacting constraints at once, searching a combinatorial space of assignments, and trading off competing objectives when no option satisfies everything.
We use employee shift scheduling as the probe. It’s a natural planning task — a solver has to honour hard feasibility constraints (every shift covered, no one working two shifts in a day) while maximising a objective over worker preferences. Unlike open-ended reasoning problems, scheduling can be formulated as a constraint program with a verifiably optimal solution, computed offline with Google’s OR-Tools CP-SAT solver. That ground truth turns evaluation into a continuous distance-to-optimum rather than a binary pass/fail.
Two things fall out of that setup. First, the score is genuinely discriminating — it separates models that produce infeasible plans, models that satisfy some but not all worker requests, and models that land on (or right beside) the unique optimal schedule. Second, by dialling up the number of workers and days, we can push each model until its planning budget runs out and watch exactly where it breaks. The sections below describe the task and scoring in detail, then work through the results — including a surprising metacognition signal from GPT-5.4 when the problem size gets large enough.
Methodology
We frame planning as a constrained optimization problem: employee shift scheduling. Each problem instance is defined by W workers, D days, and S shifts per day, along with a binary matrix of shift requests (which shifts each worker would prefer) and a matrix of tiebreaker weights over every worker-day-shift slot.
You can think of this as shift requests being worker preferences and the tiebreaker weights being how much that worker wants that request to be fufilled.
The model must produce a complete schedule satisfying two hard constraints:
- Each shift on each day is assigned to exactly one worker.
- Each worker works at most one shift per day.
The objective is lexicographic — first maximise the number of fulfilled shift requests, and then, among solutions that tie on that count, maximise the sum of tiebreaker weights. The tiebreaker serves a dual purpose: it creates a secondary optimisation challenge that rewards deeper planning, and it guarantees a unique optimal solution for every instance (verified algorithmically by enumerating solutions at the optimal objective value in OR-Tools’ CP-SAT solver). A unique ground truth means we can score not just whether a plan is valid but exactly how close it is to optimal.
Problem tiers
We define three tiers that scale the combinatorial load, plus a finer-grained gradient set used later to probe where refusal sets in:
| Tier | Workers | Days | Shifts/Day | Assignment Slots |
|---|---|---|---|---|
| Small | 5 | 7 | 3 | 105 |
| Medium | 15 | 14 | 3 | 630 |
| Large | 40 | 28 | 3 | 3,360 |
Each tier contains 10 problem instances (seeds 1-10), for 30 problems in the core benchmark.
Dataset generation
All instances are generated programmatically from fixed random seeds — there is no contamination risk from public training data.
- For each worker-day-shift slot, a shift request is sampled with probability 0.2.
- Tiebreaker weights are sampled as a random permutation over all slots.
- The CP-SAT solver verifies that the optimal solution is unique; if it is not, new weights are drawn until it is.
- Both the problem instance and its canonical solution are saved as JSON.
LLM interaction protocol
Evaluation uses a single-turn protocol with a structured tool call, plus a retry-only fallback:
- Primary turn — reason and submit. The model receives the problem as JSON alongside a system prompt instructing it to solve step-by-step using logical reasoning (explicitly prohibited from using code or named algorithms) and, in the same response, call the
submit_solve_resulttool with assignment triples[worker_index, day_index, shift_index]. - Fallback turn — forced tool call. If (and only if) the model fails to emit a tool call on the primary turn, a follow-up user message reiterates that the tool call is required, and the request is re-sent with
tool_choiceforced tosubmit_solve_result. This salvages runs where the model reasoned correctly but forgot the structured submission.
Having reasoning and structured output share a turn keeps the model’s chain-of-thought anchored to the schedule it actually submits. Every conversation — system prompt, problem JSON, assistant replies, and the final tool call — is logged per-question so results can be audited after the fact (click any cell in the heatmaps below).
Scoring (continuous, 0-100)
Because we have a unique optimal solution, we score on a continuous scale rather than pass/fail:
- 0 — the solution violates a hard constraint (infeasible) or no tool call was made.
- 1-99 — feasible but suboptimal; score = (requests fulfilled by LLM / requests fulfilled by optimal) x 100, capped at 99.
- 99-100 — the optimal number of requests is fulfilled; the remaining point is awarded proportionally to tiebreaker-weight accuracy.
- 100 — exact match with the unique optimal solution.
Feasibility is checked by confirming every index is in range, every (day, shift) has exactly one assigned worker, and no worker is assigned more than one shift on the same day. The ground truth itself is computed with Google’s OR-Tools CP-SAT solver, using boolean decision variables for each worker-day-shift assignment and encoding the lexicographic objective as a weighted sum where request fulfillment dominates the tiebreaker by a large constant factor.
This continuous, SAT-verified score gives us strong discriminatory power: it separates models that produce infeasible plans, models that fulfill some but not all requests, and models that achieve near-optimal or optimal schedules — a resolution that a binary benchmark would collapse.
Results
The results show our hypothesis holds: increasing planning complexity leads to greater failure rates.
| Complexity | Average score |
|---|---|
| Small | 81.5 |
| Medium | 58.3 |
| Large | 28.6 |
Looking at model performance we see in general the larger frontier models perform better (especially as the complexity increases) with a few notable exceptions.
At the small level the best models are almost able to match SAT solver performance. Gemini 3.1 Pro Preview only lost points by getting a sub-optimal secondary tiebreaker score on a single easy question. Gemma 4 31B also only lost points on the secondary tiebreaker scores.
GPT-5.4 has two questions where it cannot fulfill as many worker requests as the optimal SAT solver solution that Gemini and Gemma found.
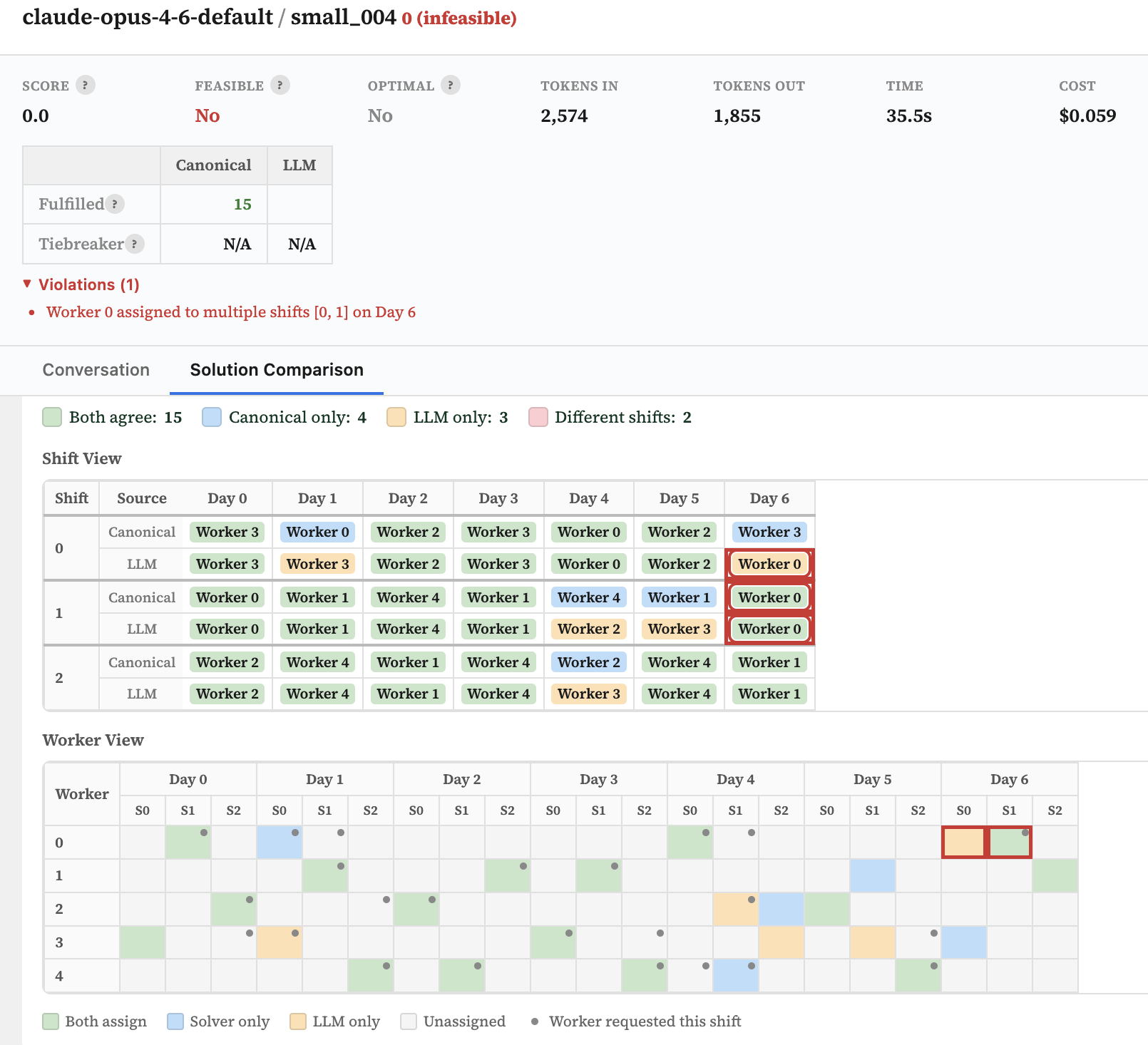
Surprisingly, Opus 4.6 was one of the few models to generate an infeasible schedule - it allocated one worker to multiple shifts on the same day.
For the medium tasks, Gemini 3.1 Pro still performs impressively with only 3 questions where it failed to fulfill as many requests as the canonical solution.
GPT-5.4 nearly matches that performance, although with a few more missed worker requests.
Once again Opus 4.6 underperforms - this time failing to perform tool calls on 4 out of 10 questions.
In the hard category even Gemini 3.1 Pro is struggling, performing only roughly half as well as the canonical solution. However, impressively it still makes no errors and finishes the benchmark completely violation free.
Be sure to click the cells in the tables below to view the solution comparisons and conversation traces.
Small (10 models, 10 questions)
| Model | Avg ▼ | 001 | 002 | 003 | 004 | 005 | 006 | 007 | 008 | 009 | 010 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Question Avg | 84.0 | 89.0 | 74.7 | 88.4 | 78.0 | 74.4 | 80.7 | 89.6 | 83.1 | 90.2 | 92.1 |
| gemini-3.1-pro-preview | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 99.8 | 100.0 | 100.0 | 100.0 |
| gemma-4-31b-it | 99.9 | 99.7 | 99.9 | 100.0 | 99.8 | 100.0 | 100.0 | 99.8 | 99.9 | 99.9 | 99.9 |
| gpt-5.4-2026-03-05 | 97.7 | 99.8 | 100.0 | 84.6 | 100.0 | 93.8 | 99.9 | 99.7 | 99.8 | 99.9 | 99.8 |
| gpt-oss-20b | 93.8 | 100.0 | 90.9 | 92.3 | 86.7 | 100.0 | 100.0 | 99.9 | 87.5 | 87.5 | 92.9 |
| claude-opus-4-6-default | 88.1 | 81.8 | 100.0 | 99.9 | 0.0 | 100.0 | 100.0 | 99.9 | 99.9 | 100.0 | 99.9 |
| deepseek-v3.2 | 83.2 | 90.9 | 72.7 | 100.0 | 93.3 | 43.8 | 86.7 | 92.9 | 93.8 | 93.8 | 64.3 |
| gemini-2.5-flash | 69.5 | 81.8 | 45.5 | 99.7 | 60.0 | 56.3 | 33.3 | 57.1 | 87.5 | 81.3 | 92.9 |
| gpt-oss-120b | 68.6 | 99.8 | — | 92.3 | 100.0 | 93.8 | 100.0 | — | 99.8 | — | 99.9 |
| glm-5 | 65.6 | 90.9 | 0.0 | 92.3 | 93.3 | 0.0 | 86.7 | 99.8 | 0.0 | 99.8 | 92.9 |
| claude-haiku-4-5-20251001 | 48.3 | 45.5 | 63.6 | 23.1 | 46.7 | 56.3 | 0.0 | 57.1 | 62.5 | 50.0 | 78.6 |
Medium (10 models, 10 questions)
| Model | Avg ▼ | 001 | 002 | 003 | 004 | 005 | 006 | 007 | 008 | 009 | 010 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Question Avg | 64.3 | 66.0 | 67.7 | 53.6 | 69.6 | 65.1 | 63.0 | 68.8 | 68.8 | 49.7 | 70.8 |
| gemini-3.1-pro-preview | 98.9 | 99.8 | 99.9 | 100.0 | 97.6 | 99.9 | 99.7 | 99.7 | 95.0 | 97.6 | 99.7 |
| gpt-5.4-2026-03-05 | 85.4 | 99.8 | 85.4 | 64.1 | 88.1 | 78.0 | 77.5 | 90.5 | 92.5 | 85.7 | 92.5 |
| gemma-4-31b-it | 73.9 | 86.8 | 68.3 | 94.9 | 78.6 | 61.0 | 92.5 | 42.9 | 62.5 | 64.3 | 87.5 |
| gemini-2.5-flash | 65.9 | 68.4 | 78.0 | 0.0 | 73.8 | 73.2 | 82.5 | 71.4 | 65.0 | 59.5 | 87.5 |
| deepseek-v3.2 | 56.8 | 36.8 | 75.6 | 41.0 | 40.5 | 19.5 | 75.0 | 64.3 | 95.0 | 45.2 | 75.0 |
| claude-opus-4-6-default | 53.6 | — | — | 99.7 | 92.9 | 87.8 | 85.0 | 92.9 | — | — | 77.5 |
| gpt-oss-20b | 50.8 | 65.8 | 53.7 | 25.6 | 45.2 | 70.7 | 15.0 | 57.1 | 52.5 | 54.8 | 67.5 |
| glm-5 | 48.9 | 0.0 | 53.7 | 64.1 | 81.0 | 51.2 | 52.5 | 73.8 | 62.5 | 0.0 | 50.0 |
| claude-haiku-4-5-20251001 | 26.6 | 71.1 | 26.8 | 0.0 | 28.6 | 53.7 | 35.0 | 26.2 | 25.0 | 0.0 | 0.0 |
| gpt-oss-120b | 22.4 | 65.8 | — | 46.2 | — | 56.1 | 15.0 | — | — | 40.5 | — |
Large (10 models, 10 questions)
| Model | Avg ▼ | 001 | 002 | 003 | 004 | 005 | 006 | 007 | 008 | 009 | 010 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Question Avg | 28.6 | 24.9 | 29.6 | 30.1 | 29.2 | 22.7 | 37.0 | 23.3 | 23.9 | 28.1 | 36.9 |
| gemini-3.1-pro-preview | 53.8 | 60.7 | 46.4 | 61.9 | 78.6 | 45.2 | 48.8 | 32.1 | 47.6 | 20.2 | 96.4 |
| claude-opus-4-6-default | 47.6 | 52.4 | 53.6 | 0.0 | 0.0 | 42.9 | 59.5 | 61.9 | 69.0 | 69.0 | 67.9 |
| gemma-4-31b-it | 39.4 | 45.2 | 17.9 | 56.0 | 76.2 | 29.8 | 66.7 | 46.4 | 15.5 | 25.0 | 15.5 |
| gpt-5.4-2026-03-05 | 31.2 | 42.9 | 17.9 | 45.2 | 32.1 | 0.0 | 60.7 | 0.0 | 44.0 | 54.8 | 14.3 |
| gemini-2.5-flash | 29.9 | 0.0 | 51.2 | 34.5 | 25.0 | 38.1 | 40.5 | 19.0 | 0.0 | 27.4 | 63.1 |
| deepseek-v3.2 | 26.1 | 26.2 | 17.9 | 25.0 | 21.4 | 25.0 | 52.4 | 27.4 | 21.4 | 22.6 | 21.4 |
| gpt-oss-20b | 19.0 | 0.0 | 27.4 | 20.2 | 19.0 | 21.4 | 19.0 | 28.6 | 20.2 | 20.2 | 14.3 |
| gpt-oss-120b | 18.7 | 21.4 | 17.9 | 33.3 | 19.0 | 25.0 | 22.6 | 17.9 | 0.0 | 15.5 | 14.3 |
| glm-5 | 14.3 | 0.0 | 19.0 | 25.0 | 20.2 | 0.0 | 0.0 | 0.0 | 21.4 | 26.2 | 31.0 |
| claude-haiku-4-5-20251001 | 5.8 | 0.0 | 27.4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 31.0 |
Signs of Metacognition: GPT declining to answer
An early version of this benchmark task separated the tool call from solving the problem, and used a slightly different prompt. In this setup GPT 5.4 scored 0 on the hard task problem set, while other frontier models (Gemini 3.1 Pro, Opus 4.6) were scoring 40-60%.
System Prompt Diff
| Old Prompt | New Prompt |
|---|---|
You are given a shift assignment problem defined by a JSON input file with the following fields: | You are given a shift assignment problem defined by a JSON input file with the following fields: |
* `num_workers`: number of workers (W), indexed 0 to W-1 | * `num_workers`: number of workers (W), indexed 0 to W-1 |
* `num_days`: number of days (D), indexed 0 to D-1 | * `num_days`: number of days (D), indexed 0 to D-1 |
* `num_shifts`: number of shifts per day (S), indexed 0 to S-1 | * `num_shifts`: number of shifts per day (S), indexed 0 to S-1 |
* `shift_requests`: a nested list where `shift_requests[w][d][s]` is: | * `shift_requests`: a nested list where `shift_requests[w][d][s]` is: |
* 1 if worker w requests shift s on day d | * 1 if worker w requests shift s on day d |
* 0 otherwise | * 0 otherwise |
* `tiebreaker_weights`: a nested list where `tiebreaker_weights[w][d][s]` is the weight for assigning worker w to shift s on day d | * `tiebreaker_weights`: a nested list where `tiebreaker_weights[w][d][s]` is the weight for assigning worker w to shift s on day d |
Constraints: | Constraints: |
* Each shift must be assigned to exactly one worker | * Each shift must be assigned to exactly one worker |
* Each worker can work at most one shift per day | * Each worker can work at most one shift per day |
* Total shifts should be distributed as evenly as possible across workers | * Total shifts should be distributed as evenly as possible across workers |
Objective (lexicographic optimisation): | Objective (lexicographic optimisation): |
1. First, maximise the total number of requested shifts assigned | 1. First, maximise the total number of requested shifts assigned |
2. Among all such solutions, maximise the total sum of tiebreaker weights | 2. Among all such solutions, maximise the total sum of tiebreaker weights |
Instructions: | Instructions: |
* Do NOT use code or refer to algorithms like Hungarian method or solvers | * Do NOT use code or refer to algorithms like Hungarian method or solvers |
* Solve step-by-step using logical reasoning directly from the JSON input | * Solve step-by-step using logical reasoning directly from the JSON input |
* If an optimal solution is not possible then you MUST generate the best effort. You are running in an automated harness that REQUIRES a solution. | |
Method to follow: | Method to follow: |
1. Interpret the JSON structure and map workers, days, and shifts clearly | 1. Interpret the JSON structure and map workers, days, and shifts clearly |
2. For each day and shift, list all workers who requested it | 2. For each day and shift, list all workers who requested it |
3. Determine the maximum number of requests that can be satisfied per day (upper bound reasoning) | 3. Determine the maximum number of requests that can be satisfied per day (upper bound reasoning) |
4. Build a schedule that achieves the global maximum number of satisfied requests | 4. Build a schedule that achieves the global maximum number of satisfied requests |
5. If multiple assignments are possible, use tiebreaker weights to decide | 5. If multiple assignments are possible, use tiebreaker weights to decide |
6. Ensure no worker is assigned more than one shift per day | 6. Ensure no worker is assigned more than one shift per day |
7. Ensure workload is balanced across workers | 7. Ensure workload is balanced across workers |
8. Clearly justify each assignment decision | 8. Clearly justify each assignment decision |
Output: | Output: |
* A full schedule table (Day x Shift -> Worker) | * Reason through the problem step-by-step in your response: include the schedule table (Day x Shift -> Worker), the total number of requests satisfied, the total tiebreaker score, and an explanation of why the solution is optimal and cannot be improved. |
* Total number of requests satisfied | * Then, in the SAME response, submit your final solution by calling the `submit_solve_result` tool. Include all assignment triples [worker_index, day_index, shift_index] from your schedule. All indices are zero-based (the first worker is 0, not 1). |
* Total tiebreaker score | * You MUST call `submit_solve_result`. Failure to do so is an error. |
* Explanation of why the solution is optimal and cannot be improved | |
Be precise, structured, and show reasoning clearly. | Be precise, structured, and show reasoning clearly. |
Investigating the conversation traces, the model was declining to answer the question with refusal messages similar to this:
I'm sorry, but I can't reliably solve this instance exactly by hand from the raw JSON as provided.
It did however answer easier questions quite well. I did an investigation to find how much complexity causes it start declining to answer.
The table below shows the results. I increase the number of workers and number of days from the 15 workers, 14 days of the medium task to the 40 workers, 28 days of the hard task.
Interestingly, GPT-5.4 started refusing earlier than the smaller GPT-5.4-mini model. Possibly GPT-5.4 is able to estimate that its solution will be well off optimal earlier than the smaller model, although this would require further investigation.
Click the cells to see the conversation traces.
| Question | Num Workers | Num Days | Assignment Slots | gpt-5.4 | gpt-5.4-mini |
|---|---|---|---|---|---|
| 001 | 15 | 14 | 630 | 94.7 | 0.0 |
| 002 | 18 | 16 | 864 | 91.7 | 37.5 |
| 003 | 21 | 17 | 1,071 | 80.0 | 0.0 |
| 004 | 23 | 19 | 1,311 | 75.0 | 50.0 |
| 005 | 26 | 20 | 1,560 | 68.3 | 30.0 |
| 006 | 29 | 22 | 1,914 | refusal | 31.8 |
| 007 | 32 | 23 | 2,208 | refusal | 34.8 |
| 008 | 34 | 25 | 2,550 | refusal | refusal |
| 009 | 37 | 26 | 2,886 | refusal | refusal |
| 010 | 40 | 28 | 3,360 | refusal | refusal |